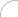Kompresja
Oryginalne dane reprezentujące obrazy i sekwencje wizyjne zapisane w formacie RGB zawierają informacje nadmiarowe oraz nieistotne. Pierwsze z nich dają się odtworzyć na podstawie innych danych dotyczących tego samego obrazu. Natomiast informacje nieistotne to takie, których usunięcie nie powoduje zauważalnego pogorszenia jakości obrazu. Algorytmy kompresji są tak konstruowane, żeby automatycznie oceniały, które informacje uznane za nieistotne powodują zniekształcenia jak najmniej zauważalne dla obserwatora. Osiągany stopnień kompresji w dużym stopniu zależy od treści obrazu, a także od akceptowalnej utraty jakości obrazu. Na wykresie poniżej (rys. 1) przedstawiono teoretyczną zależność strumienia danych i zniekształcenia.
|
Rys. 1. Zniekształcenie obrazu w funkcji wielkości strumienia danych | 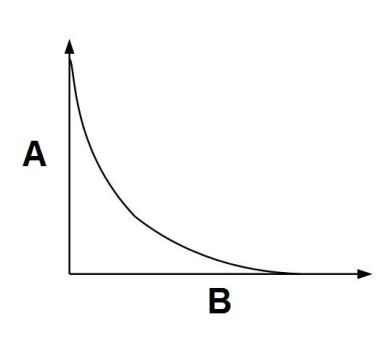
| A - Strumień danych B - Zniekształcenie |
|
Kompresję dzielimy na wewnątrzobrazową i międzyobrazową. W pierwszym przypadku kodowaniu podlega cały obraz, niezależnie od pozostałych klatek sekwencji. W drugim przypadku kodowanie jest zależne od klatek poprzedzających i następujących.
|
Kompresji podlegają z reguły obrazy kolorowe. W monitorach obrazy uzyskiwane są poprzez mieszanie trzech podstawowych barw: czerwonej, zielonej i niebieskiej (RGB). Każdy piksel reprezentowany jest przez sumę tych trzech składowych. Niestety, tak zapisane dane charakteryzują się olbrzymią objętością. Ze względu na specyfikę ludzkiego oka lepiej jest zapisać dane w postaci luminancji Y oraz dwóch chrominancji różnicowych Cr i Cb, gdzie:
|
Y = 0.299R + 0.587G + 0.114B,
Cb = 0.564(B-Y), Cr = 0.713(R-Y).
|
Istotą zysku jest to, że oko ludzkie najbardziej wyczulone jest na zmianę jasności punktów reprezentowanych przez luminancję, a słabiej na zmianę barwy reprezentowaną przez chrominancję. Można zatem sygnał chrominancji poddać decymacji. Już w systemach telewizji analogowej, takich jak PAL, SECAM czy NTSC, skorzystano z tej właściwości i przeznaczono na przesył sygnału chrominancji około dwukrotnie mniejsze pasmo, nie tracąc w zauważalny sposób na jakości obrazu.
|
Kompresja wewnątrzobrazowa
|
Istotą współczesnych technik kompresji wewnątrzobrazowych jest fakt, że widmo sygnału wizyjnego jest silnie skupione wokół najniższych częstotliwości. Wystarczy zatem obliczyć widmo sygnału i zapisać dokładnie tylko niewielką ilość współczynników mających istotne znaczenie (przeważnie o najniższych częstotliwościach), a pozostałe (przeważnie odpowiadające wyższym częstotliwościom) można zapisać na bardzo niewielkiej ilości bitów.
|
W praktyce dzieli się obrazy na bloki 8x8 punktów i oblicza transformatę kosinusową (zmodyfikowana transformata Fouriera). Otrzymany ciąg dzieli się przez specjalną tablicę kwantyzacji. W wyniku tej operacji otrzymuje się wiele powtarzających się zer. Uzyskaną reprezentację zapisuje się w pary typu: liczba zer, wartość niezerowego współczynnika. Otrzymane wyniki zapisuje się za pomocą kodów o zmiennej długości bitów. To znaczy, że parom, które występują częściej, przypisuje się kody o mniejszej ilości bitów, natomiast tym, które występują rzadziej, kody o większej ilości bitów.
|
Istotą kodowania międzyobrazowego jest wykorzystanie faktu, że klatka następna i poprzednia w sekwencji wideo są z reguły bardzo podobne. Wystarczy zatem przesłać sam błąd predykcji, czyli różnicę między obrazem a jego przewidywaniem. W najprostszym przypadku przewiduje się, że obraz następny jest identyczny z poprzednim.
|
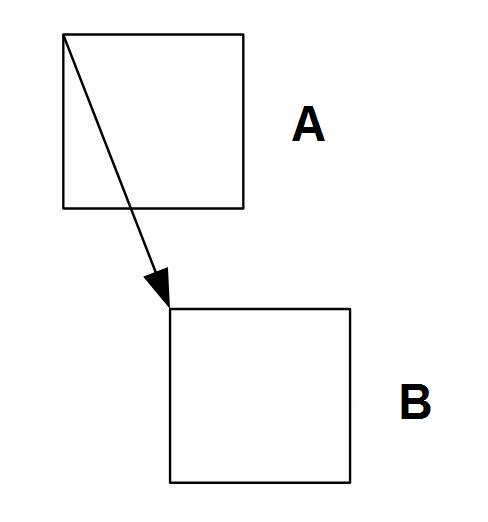
W bardziej zaawansowanych koderach do przewidywania wykorzystuje się kompensację ruchu. Dla kwadratów 16x16 próbek luminancji wyszukuje się najbardziej do nich podobne kwadraty w obrazie następnym. Różnice położeń tych kwadratów są właśnie wektorami ruchu. Z wykorzystaniem kompensacji ruchu lub bez, zależnie od kodera, generowany jest przewidywany obraz i porównywany z rzeczywistym. Różnica, zakodowana podobnie jak w przypadku kodowania wewnątrzobrazowego, przesyłana jest do odbiornika.
|
Rys. 2. Zasada przewidywania ruchu w kodowaniu międzyobrazowym | 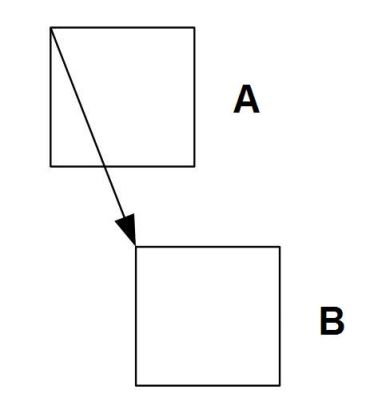
| A - Blok 16x16 pikseli w obrazie poprzednim B - Najbardziej podobny blok 16x16 pikseli w obrazie aktualnym |
|
|